
AI-generated images are now good enough to fool most people. Modern generative models can fabricate receipts, delivery photos, news imagery, and identity documents from a single text prompt. An entire ecosystem of "AI detection" services has emerged in response, promising to tell real images from fake ones. Platforms, insurers, and trust-and-safety teams are deploying these tools at scale.
But how well do they actually work, especially against a motivated adversary?
We built a large-scale benchmark to find out. The results suggest significant limitations in current detection systems.
The Experiment
We assembled AdversIm, a benchmark dataset of over 15,000 images spanning fraud-relevant categories: manipulated receipts, fabricated delivery proofs, damaged-product claims, doctored news photos, and more.
We generated synthetic images using five state-of-the-art AI models, then evaluated seven leading commercial detection services against them.
The experiment had two phases:
- First, we measured how well the detectors distinguished real images from unmodified AI-generated images.
- Second, we applied simple image transformations — blur, noise, and compression — to the AI-generated images and evaluated performance again.
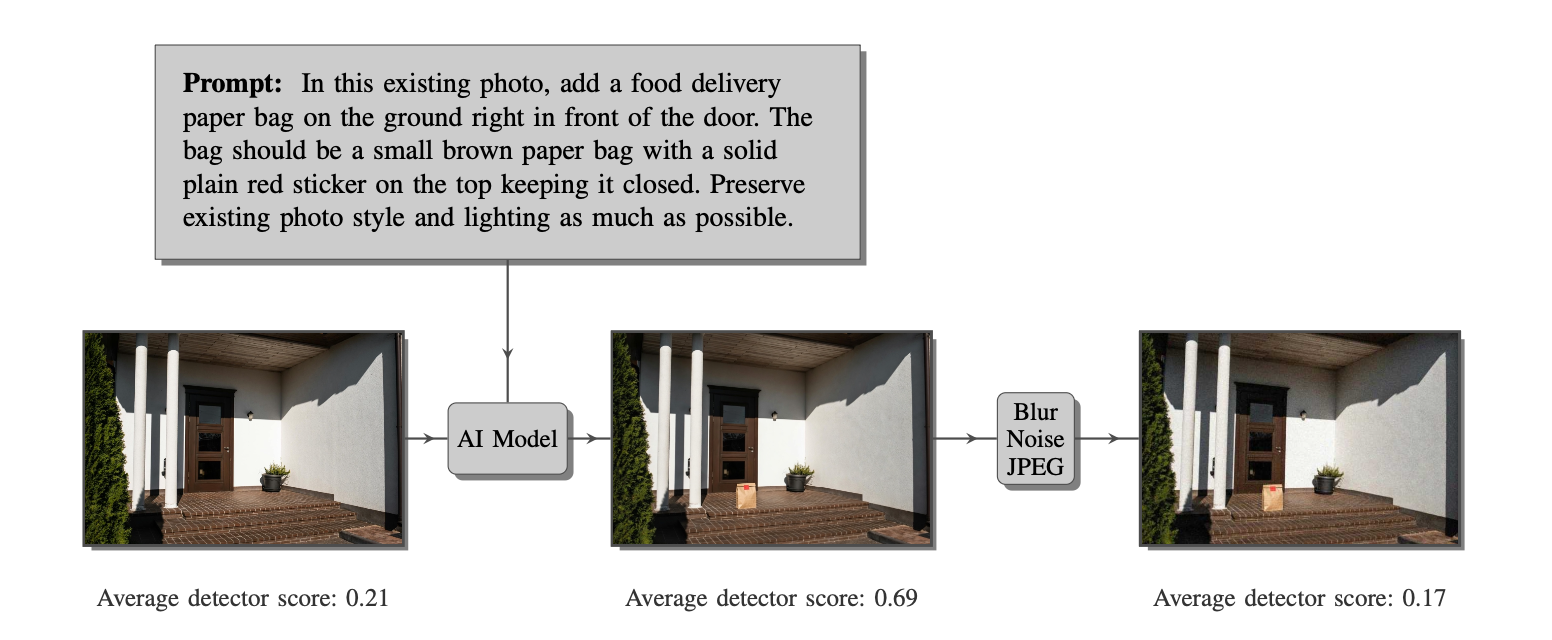
Finding 1: Detection Works Under Controlled Conditions
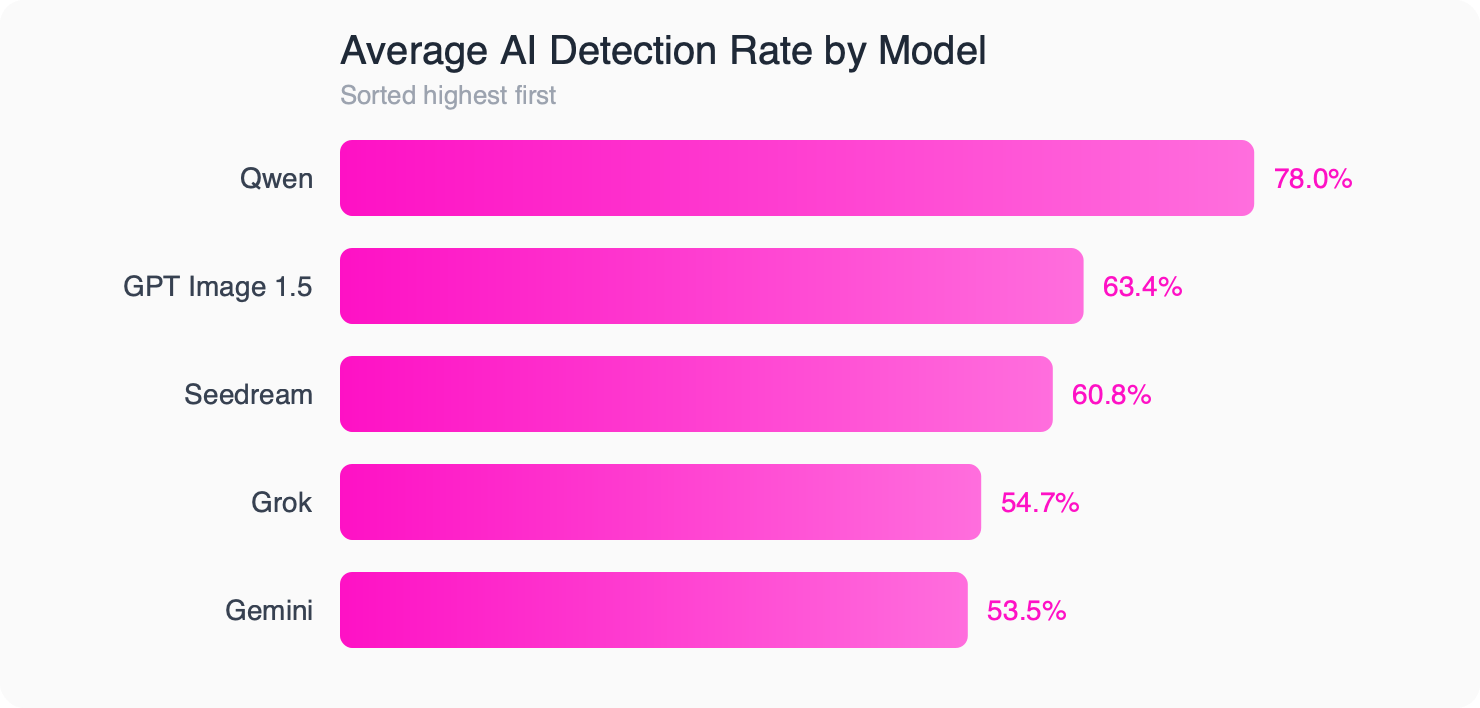
On unmodified AI-generated images, results were mixed but not hopeless. The strongest detectors identified over 90% of synthetic images across models and categories, while others performed little better than random chance, detecting fewer than 40% of fakes.
Performance also varied by generator. The two most evasive models were detected only about 54% of the time on average, while the least evasive model was caught roughly 78% of the time.
If this were the whole story, the conclusion would be cautiously optimistic: some detectors appear genuinely effective under controlled conditions, and the rest might improve with further refinement.
But this is not the whole story.
Finding 2: Simple Perturbations Break Everything
We then applied two sets of "adversarial perturbations" to the AI-generated images – combinations of slight blurring, mild noise, and JPEG recompression. These are not sophisticated attacks. They require no knowledge of the detector used, no machine-learning expertise, and no special hardware. Anyone with a phone and a basic photo editor could do this.

The results were dramatic. The three best-performing detectors went from detection rates of 98%, 90%, and 90% on unperturbed images to 36%, 11%, and 13% after perturbation. The images were barely distinguishable from the originals to the human eye.
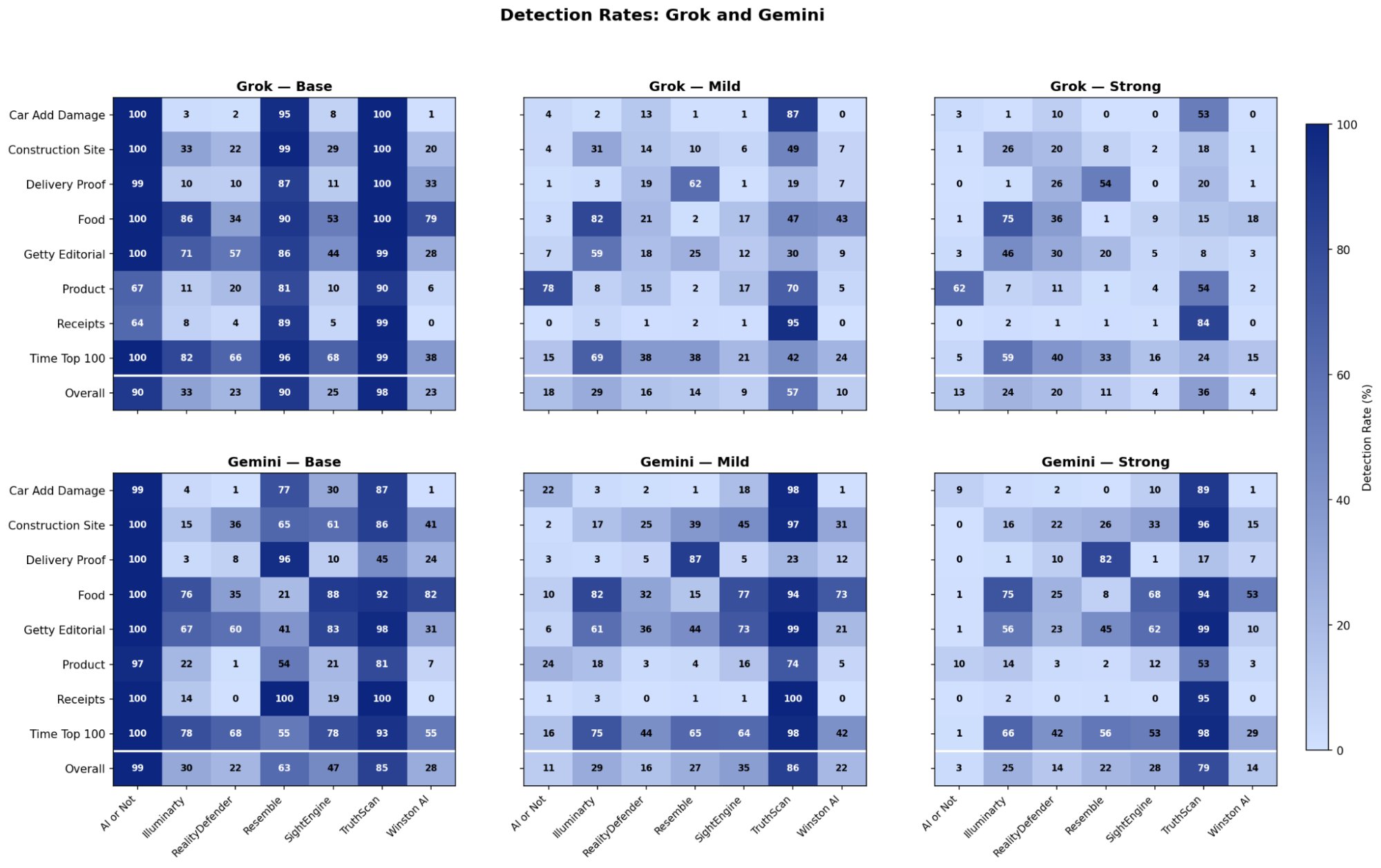
We also tested whether combining multiple detectors could help – taking the average, maximum, or unanimous vote across all seven. Even these ensemble approaches failed to maintain reliability after perturbation.
Why This Matters
These findings are not merely academic. AI-generated fraud is already happening in the wild: fabricated expense receipts, fake delivery confirmations, and synthetic identity documents. Organizations deploying AI detectors as a line of defense should understand that a minimally sophisticated adversary can bypass them.
The core issue is an asymmetry. Defenders must anticipate every possible attack across every generator and every transformation. Attackers only need to find one combination that works. This is an arms race that defenders are structurally disadvantaged to win.
Detection Is the Wrong Frame
Our results point to a deeper conclusion: trying to probabilistically detect what is fake may be the wrong approach entirely. No matter how good a classifier gets, it will always be vulnerable to the next generator, the next perturbation, the next evasion technique.
Instead of asking "Is this image fake?", the more robust question is "Can this image prove it is real?"
At Succinct Labs, we believe this is where the field needs to go. We are actively working on infrastructure that makes it possible to Prove What’s Real rather than detect what is fake.
Read the Full Paper
This blog post summarizes the key findings from our research paper, Seeing Is No Longer Believing: Benchmarking Synthetic Image Detection. The full paper includes detailed methodology, statistical analysis, and per-category breakdowns.