SP1 Benchmarks: 8/6/24


Our updated performance benchmarks for SP1’s latest production-ready release (v1.1.1). Experience unparalleled performance with our new GPU prover.
TL;DR: SP1’s new GPU prover achieves state of the art performance, with the cheapest cloud costs vs. alternative zkVMs by up to 10x, across a diverse set of blockchain workloads like light clients and EVM rollups.
SP1’s performance has improved by an order of magnitude since our launch in February, thanks to relentless performance engineering and our new GPU prover. With SP1’s v1.1.1 release, SP1 is the market-leading zkVM on both performance and cost for workloads like light clients and EVM rollups.
Get started with our latest prover today through the beta version of Succinct’s prover network (sign up here). Top teams like Polygon, Celestia, Avail and more have already generated more than 10,000 proofs and proven trillions of cycles on our prover network.
SP1’S NEW GPU PROVER ACHIEVES STATE-OF-THE-ART PERFORMANCE WITH UP TO 10X+ CHEAPER CLOUD COSTS
We benchmark SP1 against RISC0 on three real-world workloads (Tendermint, Reth Block 17106222, and Reth Block 19409768) using a variety of cost-efficient AWS and Lambda Labs GPUs with on-demand pricing.
We note that RISC0’s latest benchmarks against SP1 misleadingly compared our CPU performance to their GPU results. We conducted a fair, apples-to-apples comparison on identical hardware, revealing the significant advantages of our highly optimized GPU prover and precompile-centric architecture.
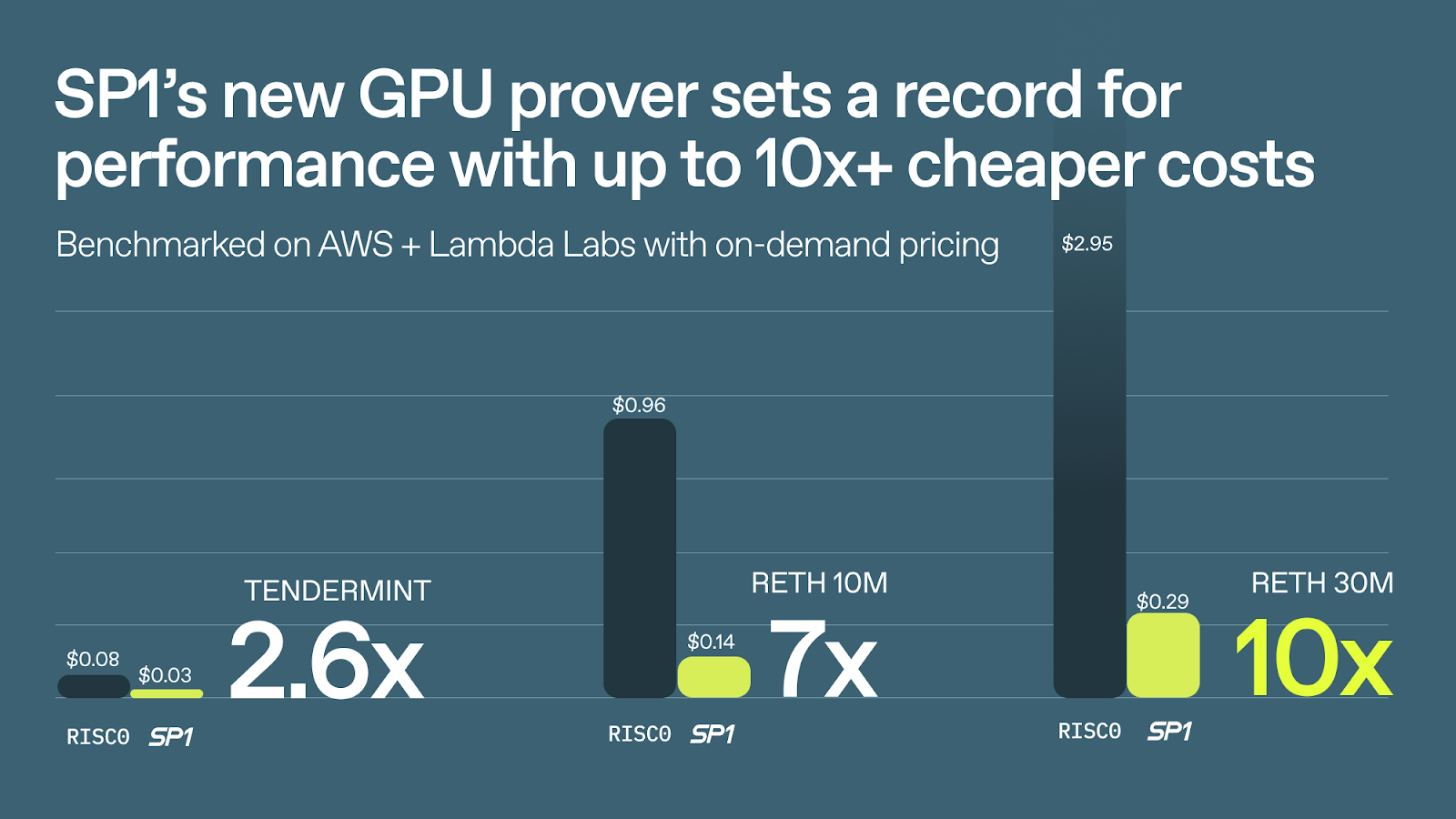
Our benchmarks are performed across a variety of GPU instances, ranging from AWS g6.xlarge, AWS g6.2xlarge, AWS g6.16xlarge, Lambda Labs NVIDIA A6000, and Lambda Labs NVIDIA A100. We report the cheapest cost across all machines for each zkVM. For more methodology and a raw data sheet, refer to the methodology section.
Key Takeaway. If you’re building a rollup, SP1’s proving costs per block are 10x cheaper than any other zkVM. With readily-available GPU instances on the cloud, SP1 already achieves around a tenth of a cent proving cost per transaction for average Ethereum blocks.
Use it today. If your team wants to take advantage of our GPU prover, it is available on our prover network beta today. Follow the instructions here to sign up. It will be officially available for local usage in the upcoming weeks.
WHY IS SP1 THE MOST PERFORMANT ZKVM?
The performance gap between SP1 and alternative zkVMs is attributable to several key factors.
SP1’s precompile-centric architecture. SP1 has support for a flexible precompile system that can accelerate any operation, including secp256k1 and ed25519 signature verification, and sha256 and keccak256 hash functions, decreasing RISC-V cycle counts between 5-10x for many programs. Most real-world workloads (especially light clients and rollups) are dominated by repetitive operations like hashing and elliptic curve operations. SP1 has been designed from the ground up to have its precompiles (which are hand-written, optimized circuits for specific operations) offer performance competitive with ZK circuits for these use-cases, while preserving the flexibility and developer experience of a zkVM.
SP1 is 100% open-source, allowing teams like Argument (formerly known as Lurk Labs) and Scroll to implement custom precompiles for their own use-cases that have dramatically decreased cycle count and accelerated proof generation time. Reach out here if you’re interested in doing something similar.
The idea of precompiles inside zkVMs has become an industry standard since we first introduced SP1, with it becoming a part of RISC0, Valida, Nexus, and Jolt's roadmaps. Today, SP1 is the only production-ready zkVM with extensive precompiles for all the cryptographic operations that matter (keccak256, sha256, secp256k1 and ed25519 signature verification, bn254 and bls12-381 arithmetic, and soon to include bn254 and bls12-381 pairing verification).
A two-phase prover for efficient read-write memory. SP1 uses a novel memory argument which uses a single challenge from the verifier to implement consistent memory across multiple proofs. Because of this, our proof system doesn’t pay the overhead of merkelized memory, which can add significant overhead to proving workloads.
Fundamental proof system efficiencies. We use a lower blowup factor (2 versus 4), use next-generation lookup arguments (i.e., the log derivative-based LogUp), and use a variant of FRI in Plonky3 that allows us to commit to tables of different sizes which gives us more efficient trace area utilization.
METHODOLOGY
We benchmark SP1 on v1.1.1 and RISC0 on v1.0.0. We describe the methodology to our benchmarks below.
- Real-world programs. We benchmark with programs that reflect genuine real-world usecases, like a Tendermint light client and Reth with 2 Ethereum blocks.
- End-to-end proving time. We measure only witness generation and proving time, excluding prover setup and verification.
- Constant proof size. Both systems generate proofs of constant size, using recursive verification of proofs for long RISC-V executions.
- Precompiles. Whenever available, we enable precompiles for both SP1 and RISC0.
- Hardware Acceleration. We enable hardware acceleration whenever available on both CPU and GPU. On CPU, SP1 has support for AVX and NEON, while RISC0 does not. On GPU, both SP1 and RISC0 have support for CUDA.
We do not benchmark against Valida and Jolt as the projects are still early in development and cannot run most of our benchmarking programs and do not have support for recursion.
Lastly, note that due to the very complex, multi-dimensional nature of zkVM performance (including factors like hardware, single-node vs. multi-node performance, memory usage, recursion cost, hash function selection) these benchmarks only present a simplified view of performance. We tried our best to provide as fair of a comparison as possible, although it is difficult for a single benchmark to capture all nuances.
All benchmarks are reproducible using the repository here and here is a full breakdown of our results.
PERFORMANCE ROADMAP
SP1’s performance is improving everyday and we expect it to continue improving significantly over the upcoming months. A quick preview of what to expect:
- A next-generation recursion system. We’re working on a new architecture for our recursion system which can combine the performance of circuit-based recursion while supporting precompiles. This will improve end-to-end performance by ~2x.
- Optimizing our two-phase prover approach. Right now we utilize a two-phase prover to have a more efficient representation of read-write memory. We recently discovered a method that will dramatically cut down the cost of phase 1 proving. This will improve end-to-end performance by 1.5x-2x.
- Better arithmetization in costly AIRs. We also have discovered better ways to arithmetize our mostly commonly used tables, such as the CPU, which will cut down proving time by another 33% for certain workloads. This will improve performance by 1.5x.
- And much more.
In the upcoming weeks, we’ll be sharing a more comprehensive overview of our performance roadmap and the future costs you can expect when proving with SP1.
INTERESTED IN USING SP1?
SP1 is chosen by the best teams for production usage of ZKPs. We’re proud to be working with incredible partners, including Polygon, Celestia, Avail, Hyperlane, Taiko, Sovereign, Nebra, LayerN, Noble, Interchain Foundation, Witness, Nubit, Alpen and many others who are using SP1 for a diversity of use-cases such as rollups, interoperability, bridging, coprocessors, proof aggregation, verifiable attestations and more.
If you’re interested in using SP1 for any of your protocol’s ZKP needs, feel free to get started with the docs and also fill out this form to schedule a call with me or Uma.



