
BTC Warp: Don't Sync, Verify

With gratitude to Jesse Zhang, Partick Insinger, and the Succinct Labs team for starting this project at ETH San Francisco, and Marc Ziade for writing the inital draft of this post.
Introduction
We present BTC Warp, a succinct, verifiable proof of Bitcoin block headers to solve light node syncing.
Today, the Bitcoin blockchain has over 1 million nodes participating in mining blocks, over 10,000 full nodes, and light nodes. These nodes are key in securing and using the Bitcoin network. Mining nodes are responsible for creating new blocks to the BTC chain, while full nodes are responsible for verifying and storing valid copies of the full ledger. Light nodes, on the the other hand, are able to interact with the Bitcoin network without needing to store full state by relying on block headers.
However, with almost 790,000 blocks mined and each block containing over 2,000 transactions, new nodes and users can need several days to sync a full Bitcoin node by downloading up-to-date and accurate state. This is incredibly time and energy consuming and poses a high barrier of entry due to hardware and network requirements. What if there was a way to instantly sync to the Bitcoin network?
We set out to solve the Bitcoin light client sync problem using zkSNARKs for zero shot sync attestation of the entire Bitcoin chain's history of work. But why light nodes? Light nodes still need over 60 MB of storage 1 to store block headers, which is infeasible for some users.
Using the succinctness property of zkSNARKs, BTC Warp allows new light clients to instantly verify the heaviest proof-of-work Bitcoin chain with significantly less storage (less than 30 kB!). Our end goal is to be able to SNARK the full Bitcoin blockchain for full nodes; light nodes are just the first step in the process.
Bitcoin Nodes
There are 3 types of Bitcoin nodes, with each playing a key role in the BTC ecosystem.
- Full nodes: Stores the entire BTC blockchain and can fully verify all rules of the Bitcoin network
- Mining nodes: Competes to produce new blocks by packaging valid transactions (and other information) into a block
- Light node: Runs a lightweight version of the Bitcoin blockchain containing block headers. This is the focus of this project
Light nodes have interesting properties: they can connect and transact on the Bitcoin network without participating in consensus or storing the full chain history. Through light clients, participants can utilize the network without steep networking and hardware requirements, enabling Bitcoin to reach massive scale. Phones, desktop wallets, and smart contracts can easily interact with the chain through light clients.
However, we still need a trustless way to know the state of and interact with the BTC chain. This is where light nodes play a key role in verifying proof-of-work (PoW) and querying other nodes for data.
Despite the benefits of light clients, most users today don't use them and rely on centralized systems. A primary challenge is the size of the BTC chain, since downloading block headers takes time and compute needs scale linearly with the size of the chain.

We asked the question: what if we can sync a light client without having to download and valdiate every block header? It turns out that downloading all BTC headers and calculating the total work for some header H is equivalent to verifying a ZK proof that header H has work W.

Recursive zkSNARKs
For those that are unfamiliar with zkSNARKs, we recommend reading Vitalik's blogpost that provides a great overview. A key takeaway is the following:
A zkSNARK allows you to generate a proof that some computation has some particular output, in such a way that the proof can be verified extremely quickly even if the underlying computation takes a very long time to run.
Going back to the BTC sync problem, what if we put the syncing algorithm inside a zkSNARK?
We started by implementing that. We used zkSNARKs to generate a succinct proof of validity of a certain header having a certain amount of work associated with it. This allows us to sync the head of the chain in constant time without downloading and verifying PoW for each header.
def total_work(headers):
work = 0
for i in headers.len:
header = headers[i]
hash = sha256(sha256(header))
difficulty = get_difficulty(header)
assert(headers[i].parentHash == sha256(sha256(headers[i - 1])))
work += 2^256 / difficulty
return (work, sha256(sha256(headers[-1])))The above pseudocode verifies for a given i, headers[i] and headers[i-1] form a chain, and then increments the total work by the work in header[i].
However, once again, the size of the BTC chain is a challenge. You can only fit ~10,000 SHAs in a circuit due to the theoretical maximum of Groth16 proving systems. BTC has over 780,000 blocks, leading to approximately 1.5 million SHAs.
A key property of certain SNARK constructions is that they can verify other SNARKs (hence the name, recursive SNARKs). Using recursive SNARKS, we can parallelize proof generation, thereby improving scalability, compute efficiency, and degree of centralization. We used Polygon's Plonky2 recursive SNARK proving system due to several benefits, such as faster proof generation and native verification on Ethereum.
Recursive SNARKs sound deceptively simple, but they are tricky to implement and require considerations about extensiblity of the proof (covered later). Recursive SNARKs can be composed to form a "proof tree" where each layer of the tree has a different circuit. Thus, we needed to write up circuits to verify the previous layers, composing proofs starting from the tree's leaves to the root node.
SNARKs are also very computationally expensive to generate. To generate the proof of validity in a reasonable time, we need to parallelize computation. This required infrastructure to coordinate a tree of proofs.2 In summary, proof generation takes roughly $5000 today, but can be optimized to be roughly $1000 for a one-time sync and even less for proof updates for new blocks.
Technical Deep Dive
zkSNARK Design
To prove the validity of history of the BTC chain, we used recursive zkSNARKs. However, we wanted the ability to prove new Bitcoin block headers that were generated, which makes our SNARK construction slightly nuanced.
A desired property is we wanted our proof generation approach to work for new Bitcoin blocks, not just existing ones. This approach would allow us to sync light clients in the future using a succinct proof instead of re-syncing. There are two flavors to recursive proofs that we considered to achieve this.
The first approach is a cyclic recursion strategy. Simply put, cyclic recursion allows a circuit to take in public inputs and an optional proof to output a valid proof combining both pieces of information. For our use case, a cyclic proof would take in block header \(b_i\) and proof for header \(b_{i-1}\) to generate a proof for \(b_i\). This inductive argument can be applied for an arbitrarily long chain. Cyclic recursion is expensive to generate proofs for all historical block headers, but cheap to prove for new blocks.
The second approach is a composable tree structure to recursion. Each layer proves a different claim for \(n_i\) proofs, and a non-leaf layer combines information from it's children nodes. This approach lends itself to parallelization but incurs \(O(log(d))\) time to update the tree for new blocks, where \(d\) is the depth of the tree. Depending on the depth of the tree, updating the tree for one new block may need to generate over 20 new proofs. Furthermore, if our tree has \(n\) leaves, we can only prove up to block header \(b_n\).
Ultimately, we chose the composable tree approach. Using a tree structure makes generating the initial proof much faster and cheaper due to parallelizability while being able to guarantee proofs for blocks that are produced far into the future.
Naive Attempt
The naive design for the BTC Warp proof tree starts by verifying block headers are valid. This is achieved by implementing the Bitcoin syncing algorithm within a zkSNARK.
Simply put, the Bitcoin block header verification algorithm checks the work of the header is less than or equal to the difficulty bits and the parent hash of the current block matches the previous header's hash. Finally, we check the header's work is valid. In a SNARK, validating the difficulty and work is simple arithmetic operations and some big number math. These operations are relatively cheap. The main cost can be attributed to the verifying the hash: SHA256 is not a SNARK-friendly hashing algorithm.
Due to this cost, we decided to use a recursive structure for our proof. We verify headers at the leaf layer, and each non-leaf layer combines the information from it's children nodes. To help with parallelization, each layer can prove a sequence of headers. For a sequence of headers, each layer's circuit proves a claim of start hash, end hash, and total work. Thus, we form the tree below.
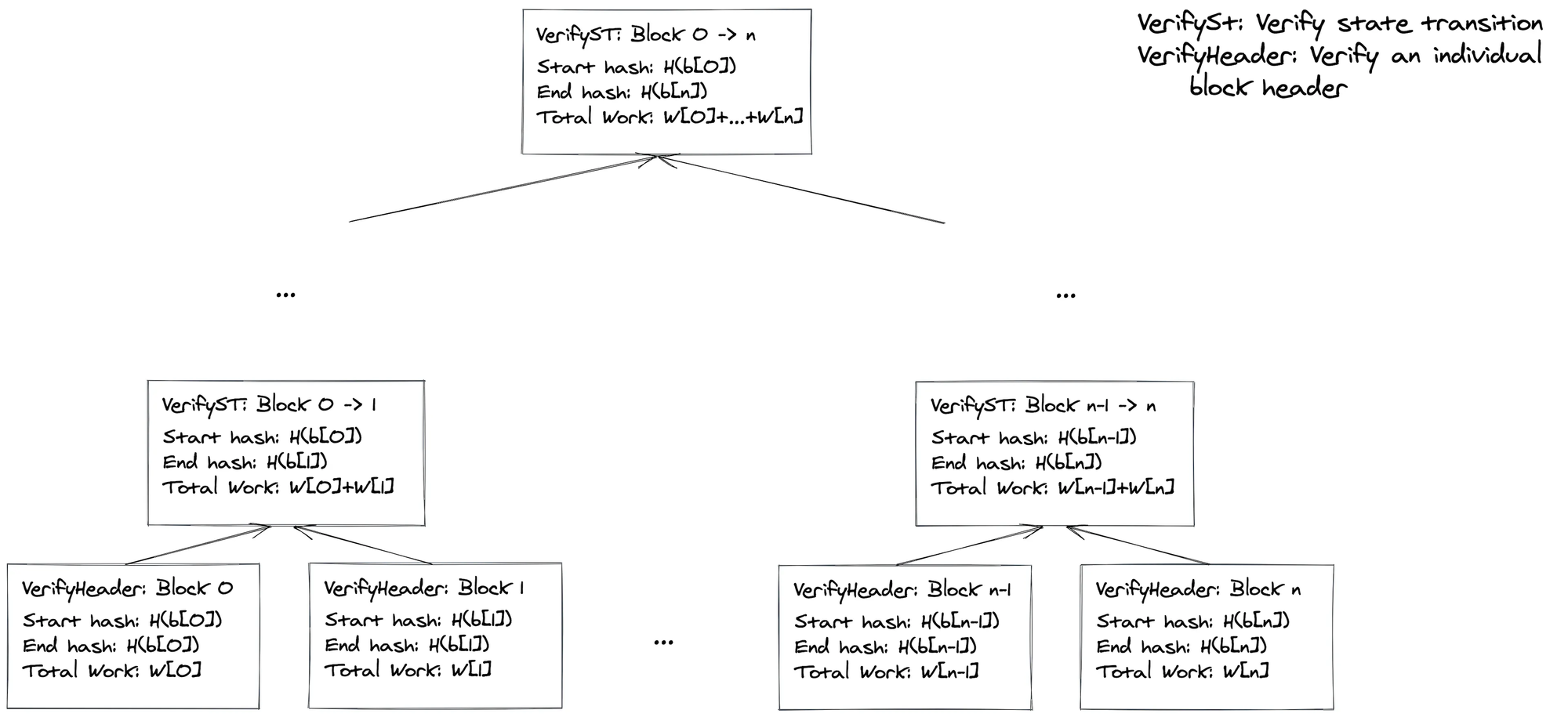
A key shortcoming of this construction is we can only prove up to block \(n\). Once the Bitcoin chain produces block \(n+1\) and onwards we need to resync our light client.
Dummy Proofs
If we need to prove up to block \(n\) in the future, we need to fill the tree with some dummy value until we get to block \(n\). But what is a valid dummy value? More importantly, how does it change our circuit?
To modify the circuit as little as possible, we chose to make a simple modification to our circuit. A key property of our initial approach was to constrain the parent hash of header \(h_i\) to be the same as the hash of header \(h_{i-1}\). Equivalently, for two proofs \(\pi_{i-1}\) and \(\pi_i\), we want proof \(\pi_{i-1}\)'s end hash to be the same as proof \(\pi_i\)'s start hash.
If we have dummy proofs, this invariant would be not met. However, we realized that the leftmost proofs in the tree would always have the valid blocks. Thus, if we encountered any cases where the end hash of proof \(\pi_{i-1}\)!= start hash of proof \(\pi_i\), we simply "forward" the end hash of proof \(\pi_{i-1}\) to the next layer of the tree! If a malicious prover was to try to forge proofs with fake blocks, the root proof's claim would only verify from block 00 to the last valid chain of blocks. "Forwarding" only valid information still gives us the desired properties from above.
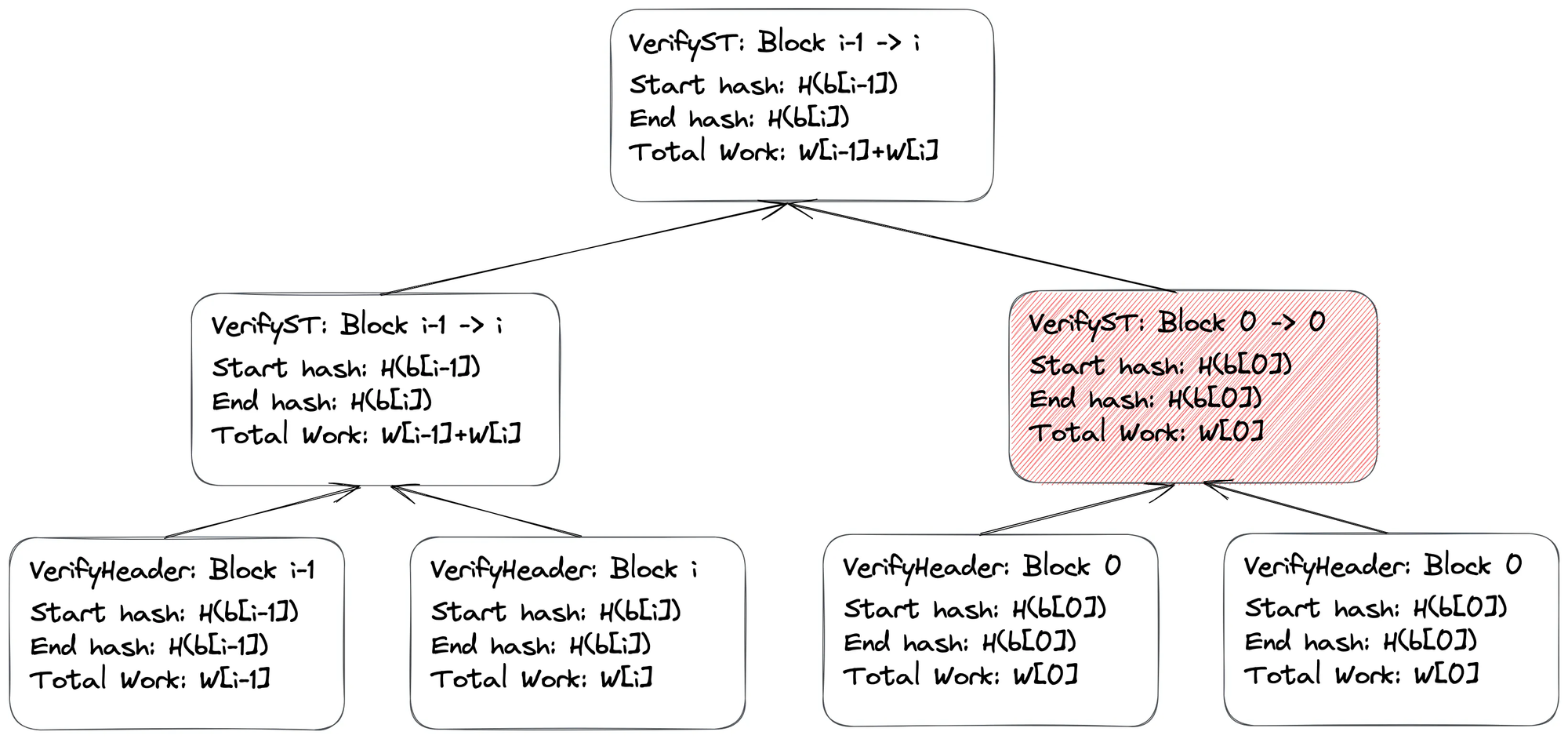
Infrastructure
Of course, our zkSNARK circuits are only a small part of this solution. A few questions we still needed to solve was how to get Bitcoin block headers and how to generate the proofs.
To get BTC block headers, we use the Nakamoto light client. Our circuits are written in Rust, so having a Rust-based light client library was desirable. We used Nakamoto to listen to network gossip to update our proof for new blocks. We created a basic API around Nakamoto to serve block headers as well, which would come in handy for our proof generation step.
Since we want to minimize time and cost to generate proofs, we wanted to exploit any parallelization opportunities. Given our tree structure and the fact that there are no data dependencies to compute proofs at a given layer. Thus, AWS Fargate is a perfect solution as it allows us to spin up as many instances as we need to parallel generation at a given layer. Furthermore, since our circuit can prove a sequence of headers at each layer, we can batch and parallelize. Each Fargate instance was spun up using Docker to generate proofs at a given layer, post the proof to a S3 bucket for usage by later instances, and then shut down.
We had to do some optimizations and benchmarking to determine the most cost and time effective way to generate the proof. Some considerations included the optimal depth of the tree for the time to update (for new blocks), the optimal number of headers to proof in a sequence, and the number of proofs to generate per Fargate instance.
To generate new block proofs, we set up a listener to our light client to detect new blocks. When new blocks were detected, a Fargate instance is spawned to do the \(O(log(d))\) updates to the proof tree.
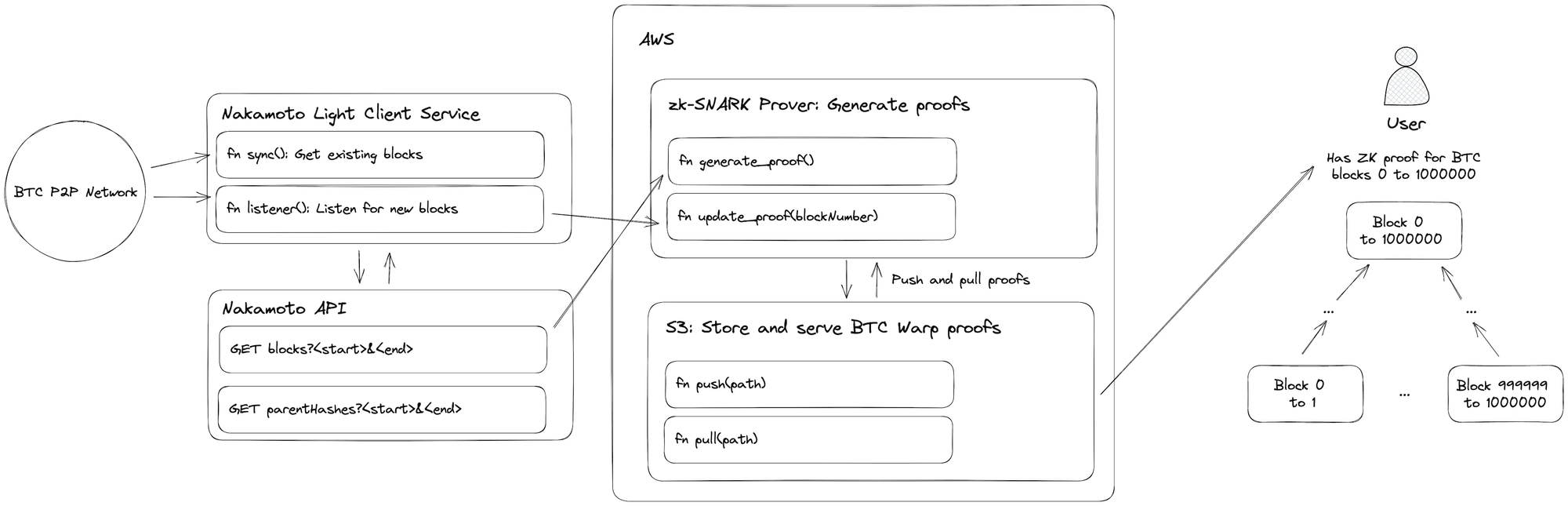
Future Work
Circuit Optimizations
As mentioned in the previous post, computing SHA256 hashes in zkSNARKs is expensive. To solve this, there are a few approaches we can take. The first is implementing a batch XOR gate in Plonky2, as outlined by the Polygon Zero team here. Essentially, we can combine several boolean constraints across several XORs into one constraint, using between 25-33% less columns than our original implementation. Another SHA optimization we can do is by implementing efficient STARKs for computing several SHA hashes together at once. This batch computation would change the structure of our design significantly, but would pay dividends in performance.
A different optimization approach we can take is focusing on circuit serialization. We noticed that creating a prover takes a large portion of time when generating proofs. However, each layer has the same prover, so why reinstantiate when we can simply serialize once and deserialize many times? At the time of writing, Plonky2 just merged in a PR for full circuit serialization, so implementing serialization support for us may also help.
Infrastructure Improvements
AWS Fargate resource limitations limited performance and increased cost for our proof generation tests. With further testing and tuning parameters such as tree height, number of proofs per proving instance, and number of proving instances, we can reduce proof generation time and costs.
Both areas of improvement listed above will be crucial for full-state proving for Bitcoin, allowing us to instantly verify all Bitcoin blocks.
Full Block Proving
Although Bitcoin block headers and blocks are two different pieces of information, constructing a Bitcoin chain proof would following the same recurisve proof structure outlined above! Therefore, we would just need to change our header verifying circuit to be a block verifying circuit. Bitcoin blocks are composed of block headers, raw transactions, and other metadata. Since we can already prove block header validity, we only need a way to prove transaction validity and inclusion within blocks! An outline on how to do so is:
- Transaction hashes to given hash transaction ID
- Transaction pays given satoshis to recipient
- Transaction ID exists in block transaction Merkle tree (Merkle tree inclusion proof)
- Transaction root is a part of block header
- Block header hashes to given block hash
The main bottleneck we face here is the size of UTXOs in a block: with several transactions per block, the full Bitcoin chain's UTXOs can take over 200GB (source) of storage. Using Utreexo and other efficient data structures within a zkSNARK, we believe full block and transaction verification is within reach.
Potential Use Cases
We’ve also thought about potential use cases where zero shot sync BTC can be used. We mention three of them below.
The first use case is about BTC Relay. BTC Relay is the first-ever production release of cross-blockchain communication of its kind. It allows Ethereum contracts3 to securely verify Bitcoin transactions without any intermediaries. BTC Relay maintains a chain of block headers. When a transaction is sent to the BTC Relay smart contract by an external party called Relayer, BTC Relay checks the validity of this header against its existing chain of block headers before adding it to the chain. You can already see here how a zero shot sync primitive could be helpful. For BTC Relay to work, it has to sync with the chain of BTC headers. Syncing is a challenge and takes time, as described above, and we have demonstrated how the primitive we’ve built solves that.
The second use case is mobile wallets. Mobile dApps need a trustless way to know the state of the chain and interact with it. Given that mobile computing power is limited, it would practically be impossible to store the whole BTC chain on your mobile. The same challenge is presented when only downloading block headers. Our zero shot sync primitive solves this problem by providing a trustless way to sync a light client without having to download and validate every block header. This in fact applies to any computing constrained environment.
Last but not least, the third use case is a recognition of the great work our friends at Geometry have been doing. Geometry announced ZeroSync, a work-in-progress tool to generate STARK proofs of the Bitcoin blockchain with the goal to create a single proof for the entire chain. SNARKs and STARKs have their differences - you can read a good summary about it in this Consensys article - but their applications will depend on the use case. We believe that these primitives will be increasingly used in the near future to build new protocols and dApps. Similarly to us, ZeroSync started by focusing on block headers with the goal of expanding their work to validate entire BTC blocks. Our zero shot BTC sync solution using SNARKs could also be expanded to provide a succinct proof of entire BTC blocks. The main advantage in this case would be saving on gas fees compared to STARKs.
Work with Us
If you have other use case ideas, we would love to hear from you.
If you’re interested in joining our team, please reach out. We are looking for strong developers with experience in Solidity and general smart contract engineering, blockchain infrastructure, and writing zkSNARK/STARK circuits.
If your blockchain ecosystem or application is interested in using our underlying primitives, please reach out here. We’re looking for a small group of early partners and would love to chat.
You can follow us on Twitter and email us at hello@succinct.xyz.
Footnotes
- With some napkin math: each header takes 80 bytes, so to store each header we need ~800,000 * 80b = 64MB.
- Fun fact: we had to call AWS support to get limits increased :P.
- We can verify the proofs on any EVM chain by verifying our Plonky2 proofs in Groth16. Groth16 proofs are cheap to verify on-chain compared to Plonky2 proofs, taking only ~200k gas.